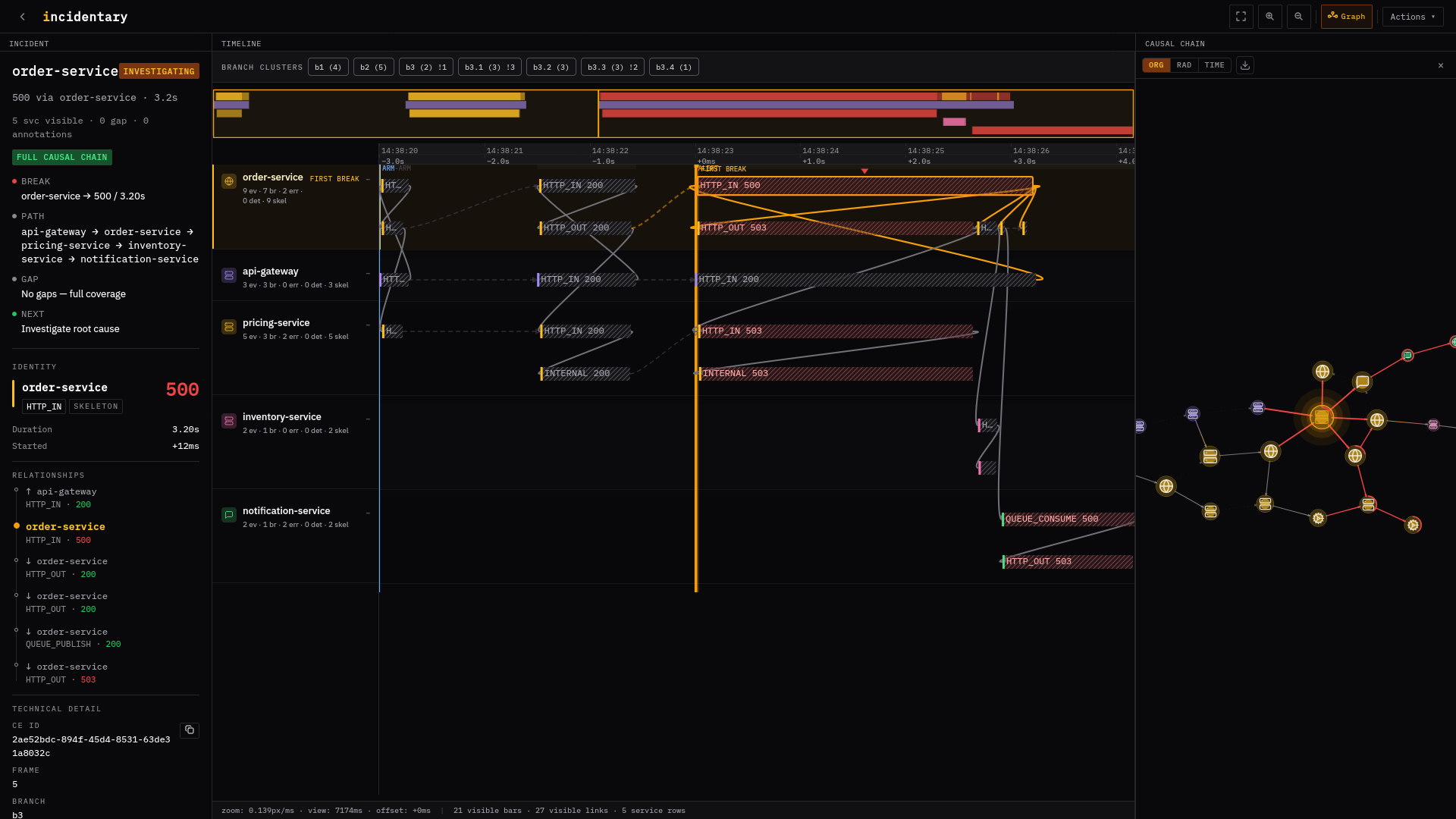
where the failure broke
session-service DB_QUERY 500
Redis GET timed out after 1.5s × 3 retries — cluster failover in progress.
where it spread
cdn-edge → checkout-service → session-service → redis
what we don't know
Whether the retry budget amplified load on the failing primary.
1 gap at warehouse-api (out of critical path)
what to look at next
Inspect Redis cluster state at redis-node-3.prod.internal:6379.
Verify session-service retry policy: 3 attempts, 1.5s each.